Refactoring the worst code I've ever written
Jacque Shrag
25 Apr 2019
•
8 min read

During the recent # DevDiscuss](https://twitter.com/search?q=%23DevDiscuss) chat on "Developer Confessions", I confessed that I didn't really know what I was doing when I started my first dev job 3 years ago. To demonstrate my inexperience, I shared an example of the kind of code I was writing at the time.
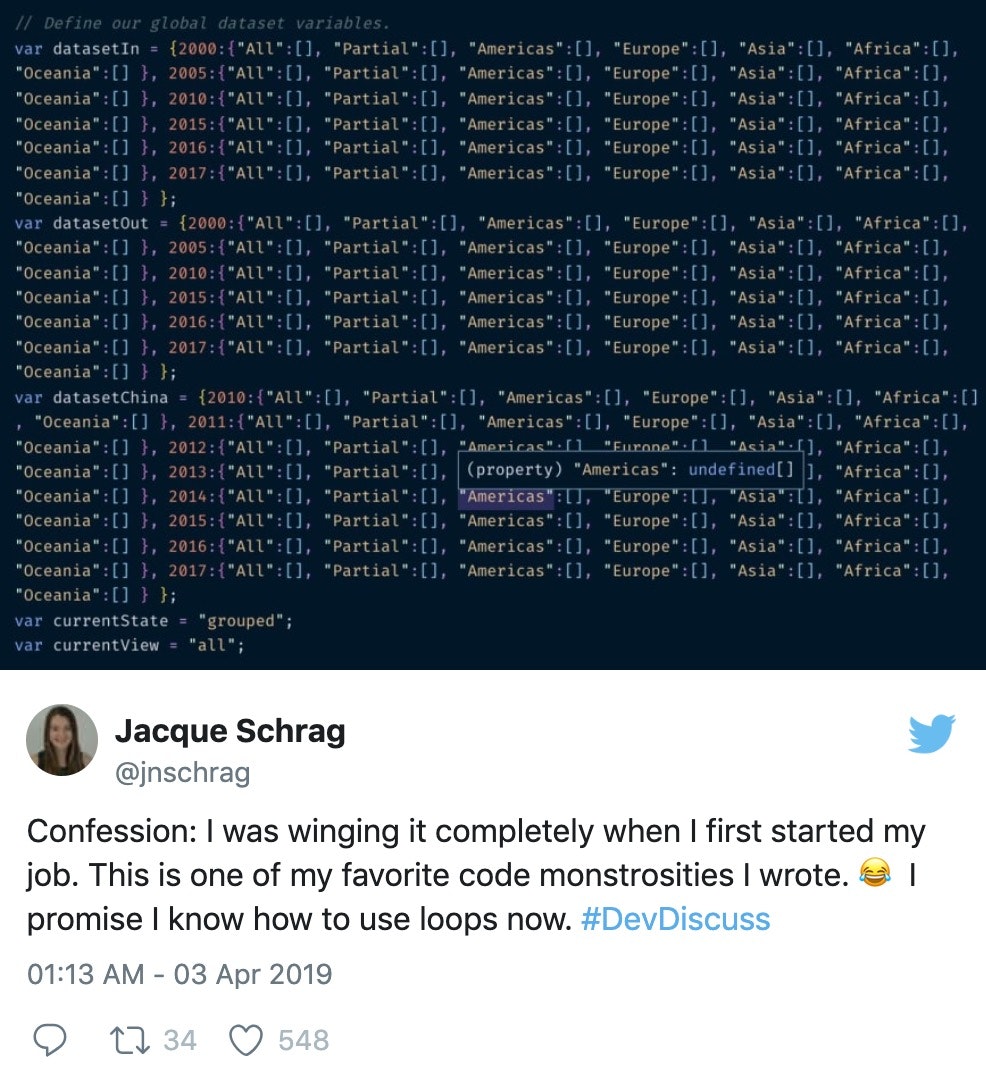
The response I received has been overwhelmingly positive. Most of us have written "bad"* code that we're not proud of, but it's a sign of growth when you can look back at that older code, recognize how it could be better, and maybe laugh at yourself for the choices you made. In the spirit of continuing to learn, I want to share some of the ways I might solve this problem today.
*Although this bit of code is silly and could have been written much more efficiently, hard-coding accomplishes the task it needed to just fine.
Context & Goals
Before refactoring any legacy code, it's critical to step-back and assess the context that the code was written in. There could be an important reason for the madness choices a developer made that were influenced by context that you might not be aware of (or remember, if it's your code). In my case, I was simply inexperienced, so this code can be safely refactored.
The code was written for two data visualizations: ["Global Foreign Direct Investment Stocks"](https://chinapower.csis.org/china-foreign-direct-investment# global-foreign-direct-investment-stocks) (in/out) and ["China Bilateral Investment Outflows"](https://chinapower.csis.org/china-foreign-direct-investment# china-bilateral-investment-outflows) (China). They have similar data & functionality, with the primary goal allowing the user to explore the datasets by filtering by type, year, or region. I'm going to focus on the global data, but the China dataset can be refactored in a similar way.
 Let's assume that changing one of the filters will result in the below values being returned:
Let's assume that changing one of the filters will result in the below values being returned:
let currentType = 'in' // or 'out'
let currentYear = 2017
let currentRegions = ['Africa', 'Americas', 'Asia', 'Europe', 'Oceania']
Note: The region checkboxes don't currently work this way, hence the "All" and "Partial" in the snippet, but this is how it should have been done. Finally, here is a simplified example of the data itself after it's been loaded in from a CSV:
const data = [
{ country: "Name", type: "in", value: 100, region: "Asia", year: 2000 },
{ country: "Name", type: "out", value: 200, region: "Asia", year: 2000 },
...
]
// Total Items in Array: ~2,400
Option 1: Initializing Empty Objects
Beyond being hard-coded, my original snippet completely violates the Don't Repeat Yourself (DRY) approach to writing code. There are absolutely instances where repeating yourself makes sense, but in this case when the same properties are being repeated over and over again, it's a smarter choice to create the objects dynamically. Doing so also reduces the amount of manual work required when a new year is added to the dataset, and limits the opportunities for input error.
There are several different approaches to making this more DRY: for, .forEach, .reduce, etc. I'm going to use the .reduce Array method, because it processes an array and transforms it into something else (in our case, an object). We're going to use .reduce three times, once per categorization.
Let's start by declaring our categories as constants. In the future, we only need to add a new year to our years array. The code we're about to write will take care of the rest.
const types = ['in', 'out']
const years = [2000, 2005, 2010, 2015, 2016, 2017]
const regions = ['Africa', 'Americas', 'Asia', 'Europe', 'Oceania']
Rather than thinking about this as types → years → regions, we want to reverse it and start with regions. Once regions is turned into an object, that object will be the value assigned to the years properties. The same is true for years in types as well. Note that it's possible to write this in fewer lines of code, but I'm opting for clarity over cleverness.
const types = ['in', 'out']
const years = [2000, 2005, 2010, 2015, 2016, 2017]
const regions = ['Africa', 'Americas', 'Asia', 'Europe', 'Oceania']
/*
Convert regions to an object with each region as a property and
the region's value as an empty array.
*/
const regionsObj = regions.reduce((acc, region) => {
acc[region] = []
return acc
}, {}) // The initial value of the accumulator (`acc`) is set to `{}`.
console.log(regionsObj)
// {Africa: [], Americas: [], Asia: [], Europe: [], Oceania: []}
Now that we have our regions object, we can do something similar for the years and types. But instead of setting their values to an empty array like we did for the regions, we set their values to the previous category's object. Edit: It was brought to my attention that the original code snippet didn't actually work once you attempted to load data into it because I was merely referencing an existing object instead of instantiating a new one. The below snippet has been updated to fix this problem by creating a deep copy of the existing object. An explanation is available in this article on "How to differentiate between deep and shallow copies in JavaScript" by Lukas Gisder-Dubé.
function copyObj(obj) {
return JSON.parse(JSON.stringify(obj))
}
/*
Do the same thing with the years, but set the value
for each year to the regions object.
*/
const yearsObj = years.reduce((acc, year) => {
acc[year] = copyObj(regionsObj)
return acc
}, {})
// One more time for the type. This will return our final object.
const dataset = types.reduce((acc, type) => {
acc[type] = copyObj(yearsObj)
return acc
}, {})
console.log(dataset)
// {
// in: {2000: {Africa: [], Americas: [],...}, ...},
// out: {2000: {Africa: [], Americas: [], ...}, ...}
// }
We now have the same result as my original snippet, but have successfully refactored the existing code snippet to be more readable and maintainable! No more copying and pasting when it comes to adding a new year to the dataset!
But here's the thing: this method still requires somebody to manually update the year list. And if we're going to be loading data into the object anyway, there's no reason to separately initialize an empty object. The next two refactoring options remove my original code snippet completely and demonstrate how we can use the data directly.
Aside: Honestly, if I had tried to code this 3 years ago, I probably would have done 3 nested for loops and been happy with the result. But nested loops can have significant negative performance impacts. This method focuses on each layer of categorization separately, eliminating extraneous looping and improving performance. Edit: Check out this comment for an example of what this method would look like and a discussion on performance.
Option 2: Filtering Directly
Some of you are probably wondering why we're even bothering with grouping our data by category. Based on our data structure, we could use .filter to return the data we need based on the currentType, currentYear, and currentRegion, like so:
/*
`.filter` will create a new array with all elements that return true
if they are of the `currentType` and `currentYear`
`.includes` returns true or false based on if `currentRegions`
includes the entry's region
*/
let currentData = data.filter(d => d.type === currentType &&
d.year === currentYear && currentRegion.includes(d.region))
While this one-liner works great, I wouldn't recommend using it in our case for two reasons:
- Every time the user makes a selection, this method will run. Depending on the size of that dataset (remember, it grows every year), there could be a negative impact on performance. Modern browsers are efficient and the performance hit might be minuscule, but if we already know that the user can only select 1 type and 1 year at a time, we can be proactive about improving performance by grouping the data from the beginning.
- This option doesn't give us a list of the available types, years, or regions. If we have those lists, we can use them to dynamically generate the selection UI instead of manually creating (and updating) it.

Yep, I hard-coded the selectors too. Every time we add a new year, I have to remember to update both the JS and the HTML.
Option 3: Data Driven Objects
We can combine aspects of the first and second options to refactor the code in a third way. The goal is to not have to change the code at all when updating the dataset, but determine the categories from the data itself.
Again, there are multiple technical ways to achieve this, but I'm going to stick with .reduce because we're going to transform our array of data into an object.
const dataset = data.reduce((acc, curr) => {
/*
If the current type exists as a property of our accumulator,
set it equal to itself. Otherwise, set it equal to an empty object.
*/
acc[curr.type] = acc[curr.type] || {}
// Treat the year layer the same way
acc[curr.type][curr.year] = acc[curr.type][curr.year] || []
acc[curr.type][curr.year].push(curr)
return acc
}, {})
Note that I've eliminated the region layer of categorization from my dataset object. Because unlike type and year, multiple regions can be selected at once in any combination. This makes pre-grouping into regions virtually useless since we have to merge them together anyway.
With that in mind, here is the updated one-liner to get the currentData based on the selected type, year, and regions. Since we're limiting the lookup to data with the current type and year, we know that the maximum number of items in array is the number of countries (less than 200), making this far more efficient than option# 2's implementation of .filter.
let currentData = dataset[currentType][currentYear].filter(d => currentRegions.includes(d.region))
The last step is getting the array of the different types, years, and regions. For that, I like to use .map and Sets. Below is an example of how to get an array that contains all the unique regions in the data.
/*
`.map` will extract the specified object property
value (eg. regions) into a new array
*/
let regions = data.map(d => d.region)
/*
By definition, a value in a Set must be unique.
Duplicate values are excluded.
*/
regions = new Set(regions)
// Array.from creates a new array from the Set
regions = Array.from(regions)
// One-line version
regions = Array.from(new Set(data.map(d => d.region)))
// or using the spread operator
regions = [...new Set(data.map(d => d.region))]
Repeat for type & year to create those arrays. You can then create the filtering UI dynamically based on the array values.
Final Refactored Code
Putting it all together, we end up with code that is future-proofed to changes in the dataset. No manual updates required!
// Unique Types, Years, and Regions
const types = Array.from(new Set(data.map(d => d.type)))
const years = Array.from(new Set(data.map(d => d.year)))
const regions = Array.from(new Set(data.map(d => d.region)))
// Group data according to type and year
const dataset = data.reduce((acc, curr) => {
acc[curr.type] = acc[curr.type] || {}
acc[curr.type][curr.year] = acc[curr.type][curr.year] || []
acc[curr.type][curr.year].push(curr)
return acc
}, {})
// Update current dataset based on selection
let currentData = dataset[currentType][currentYear].filter(d => currentRegions.includes(d.region))
Final Thoughts
Cleaning up syntax is only a small part of refactoring, but often "refactoring code" really means reconceptualizing the implementation or relationship between different pieces. Refactoring is hard because there are several ways to solve problems. Once you've figured out a solution that works, it can be hard to think of different ones. Determining which solution is better is not always obvious, and can vary based on the code context and frankly, personal preference. My advice to getting better at refactoring is simple: read more code. If you're on a team, actively participate in code reviews. If you're asked to refactor something, ask why and try to understand how others approach problems. If you're working alone (as I was when I first started), pay attention when different solutions are offered to the same question and seek out guides on best code practices. I highly recommend reading BaseCode by Jason McCreary. It's an excellent field guide to writing less complex and more readable code, and covers a lot of real world examples. Most importantly, accept that you're going to write bad code sometimes and going through the process of refactoring - making it better - is a sign of growth and should be celebrated.

WorksHub
Jobs
Locations
Articles
Ground Floor, Verse Building, 18 Brunswick Place, London, N1 6DZ
108 E 16th Street, New York, NY 10003
Subscribe to our newsletter
Join over 111,000 others and get access to exclusive content, job opportunities and more!