What's New in Deep Learning Research: Parameter Noise & The Sentiment Neuron
Jesus Rodriguez
30 Apr 2018
•
5 min read

Knowledge Exploration with Parameter Noise

The exploration vs. exploitation dilemma is one of the fundamental balances in deep reinforcement learning applications. How much resources to devote to acquire knowledge that can improve future actions versus performing specific actions? This is one of the main heuristics that rule the behavior of reinforcement learning systems. In theory, optimal exploration should always conduce to more efficient knowledge but this is far from true in the real world. Developing techniques to improve the exploration of an environment is one of the pivotal challenge of the current generation of deep reinforcement learning models. Recently, researchers from OpenAI published a research paper that proposes a very original approach to improve the exploratory capability of reinforcement learning algorithms by nothing else than introducing noise.
To understand the challenge with exploration in deep reinforcement learning systems think about researchers that spend decades in a lab without producing results with any practical application. Similarly, reinforcement learning agents can spend a disproportional amount of resources without producing a behavior that converge to a local optimum. This happens more often than you think as the exploration model is not directly correlated to the reward of the underlying process. The OpenAI team believes that the exploratory capability of deep reinforcement learning models can be directly improve by introducing random levels of noise in the parameters of the model. Does it sounds counterintuitive? Well, it shouldn’t. Consider the last time to learn a practical skill, such as a board game, by trial and error. I am sure you can recall instances in which you were challenging the conditions of the environment( such as the game rules) in order to solidify your knowledge. That’s effectively introducing noise in the input dataset J.
The OpenAI approach is not the first technique that proposes to improve exploration by introducing noise in a deep learning model. However, most of its predecessors focused on what is known as Action-Space-Noise approaches which introduce noise to change the likelihoods associated with each action the agent might take from one moment to the next. In that approach, it is very likely to obtain a different action whenever that state is sampled again in the rollout, since action space noise is completely independent of the current state. OpenAI proposes an alternative, called Parameter-Space-Noise, that introduces noises in the model policy parameters at the beginning of each episode. The Parameter-Space-Noise technique almost guarantees that the same action will be applied every time the same state in sampled from the input dataset which improves the exploratory capabilities of the model.
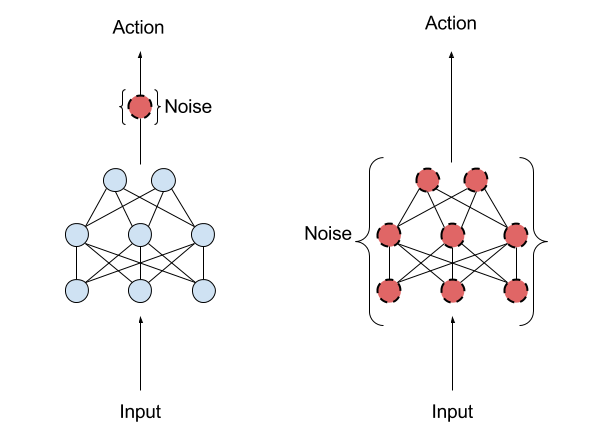
The Parameter-Space-Noise technique works very nicely with existing exploration models in deep reinforcement learning algorithms. Like some of its predecessors, the OpenAI researchers encountered some challenges
- Different layers of the network have different sensitivities to perturbations.
- The sensitivity of the policy’s weights may change over time while training progresses, making it hard for us to predict the actions the policy will take.
- Picking the right scale of noise is difficult because it is hard to intuitively understand how parameter noise influences a policy during training.
The research paper proposes solutions to tackle these challenges using well-known optimization techniques in the deep learning space.
The initial results of the Parameter-Space-Noise model proved to be really promising. The technique helps algorithms explore their environments more effectively, leading to higher scores and more elegant behaviors. This seems to be correlated to the fact that Parameter-Space-Noise adds noise in a deliberate manner to the parameters of the policy makes an agent’s exploration consistent across different timesteps. More importantly, the Parameter-Space-Noise technique is relatively simple to implement using the current generation of deep learning frameworks. The OpenAI team released an initial implementation as part of its reinforcement learning baselines.
The Sentiment Neuron
Representation learning is one of the most important techniques in modern deep learning systems. By representation learning, we are referring to models that can learn the underlying knowledge representations of a dataset in a way that can be used by other models. Transfer learning is one of the most popular forms of representation learning that can be found in most deep learning toolkits in the market. Broadly speaking, there are two main forms groups of representation learning techniques that can be found in deep learning systems.
The supervised training of high-capacity models on large labeled datasets is critical to the recent success of deep learning techniques for a wide range of applications such as image classification, speech recognition, and machine translation. There is also a long history of unsupervised representation learning which can be considered the Holy Grail in the space due to its ability to scale beyond only the subsets and domains of data that can be cleaned and labeled given resource, privacy, or other constraints. While supervised representation learning clearly dominates the current state of the market, researchers have long dreamed with unsupervised models that can learn reusable representations of knowledge. Collecting data is easy, but labeling data at scale is hard and, many time, resource prohibited.
Unsupervised sentiment analysis is one of the most active areas of research in the representation learning space. Learning topics, phrases and sentiment over large amounts of unlabeled texts is one of the representation learning techniques that can yield immediate positive results in real world deep learning applications. Imagine that we can identify the specific segment of a deep neural network responsible for the sentiment knowledge and that we can reuse that across other models. Wouldn’t that be great? Recently, researchers from OpenAI published a paper in which they outline the concept of a specific unit of a neural network responsible for the concept of sentiment: a sentiment neuron.
The discovery of the sentiment neuron was a little bit of a surprising coincidence. The original OpenAI research was focused on training a long-short-term-memory model to be able to predict the next character in the text dataset of Amazon product reviews. When going through the model regularization process, data scientists discovered that a single unit of the network was highly predictive of the sentiment of the text. Even when the model was trained to predict characters in a text, the sentiment neuron within the model was able to classify reviews as negative or positive.
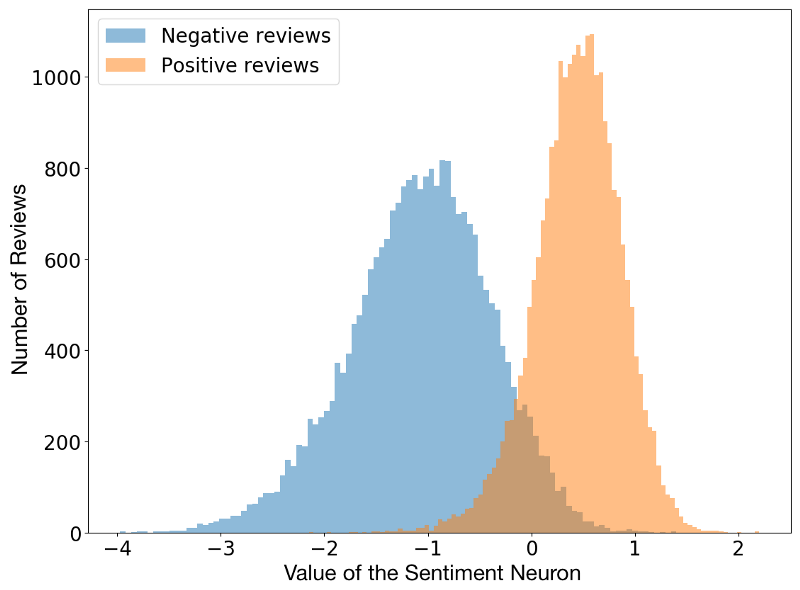
The OpenAI researchers suspect that the sentiment neuron is not an exclusive property of their LSTM model and rather a common feature of large deep neural networks that operate on high volume text datasets. To prove that point, the OpenAI team applied the sentiment neuron against a dataset of Yelp reviews providing encouraging results.
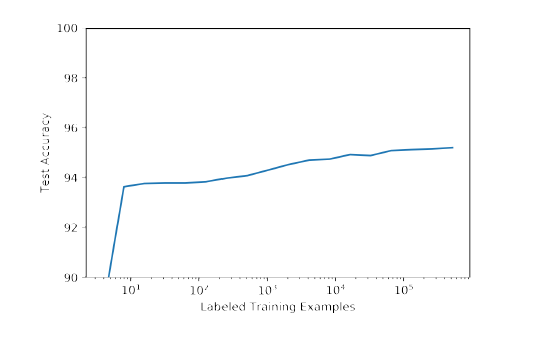
The OpenAI sentiment neuron was not without issue and the model struggle in other setting but, nonetheless, it represents a major breakthrough in the unsupervised representation learning space. What the sentiment neuron technique teaches us is that sentiment can be expressed as an accurate, disentangled, interpretable and manipulable way. It is possible that sentiment as a conditioning feature has strong predictive capability for language modelling.

WorksHub
Jobs
Locations
Articles
Ground Floor, Verse Building, 18 Brunswick Place, London, N1 6DZ
108 E 16th Street, New York, NY 10003
Subscribe to our newsletter
Join over 111,000 others and get access to exclusive content, job opportunities and more!